
Machine Learning is broadly divided into 3 types:
-
Supervised learning
-
Unsupervised learning
-
Reinforcement learning
\
Supervised Learning
The task in supervised learning is to learn a function to map a data X to a label y. All the classification, regression, object detection/recognition/segmentation generally comes under supervised learning.

 In supervised learning we have a dataset which contains data X and label y and we need to learn how to find y given X.
In supervised learning we have a dataset which contains data X and label y and we need to learn how to find y given X.
Unsupervised Learning
In unsupervised learning, we only have X and not the respective y. The goal is to learn the underlying structure/features of the dataset without any label.
Some examples of Unsupervised Learning are
-
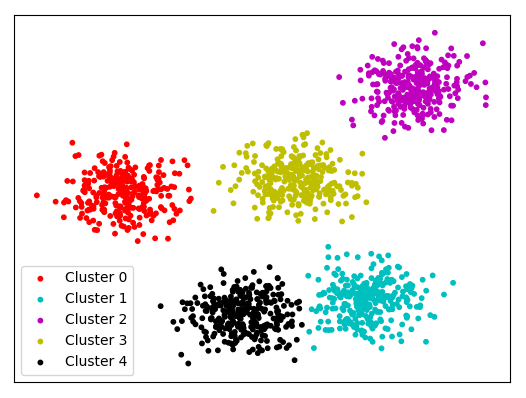
Clustering
Clustering is dividing the data into groups through some distance metric, like kmeans clustering.
-
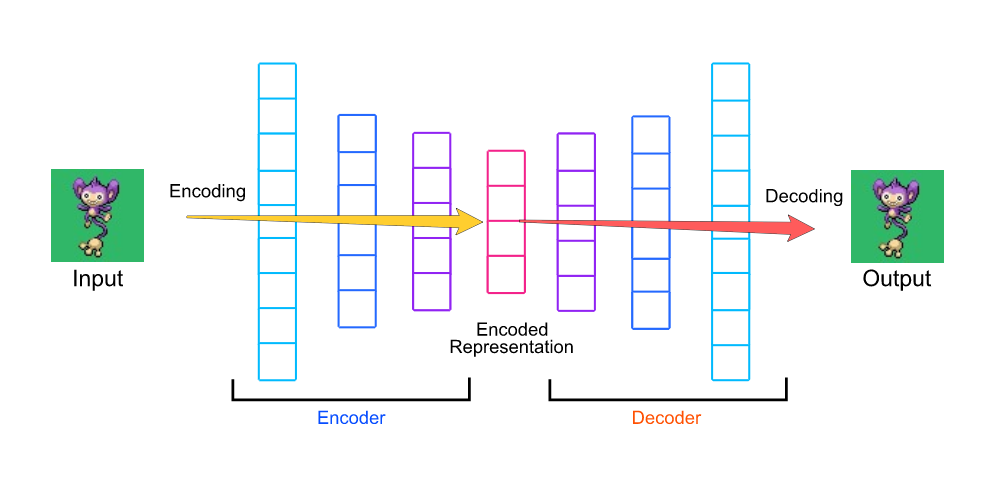
Feature Learning
As the name suggest, learning the features of each of the given data, without its label. This is generally done with a help of a model called Autoencoders.\ Autoencoders take the data X as the label y , it try to recreate the data X given data X and learns some underlying features in that process. We generally take the one of the middle layers of the autoencoder as the encoded feature.
-
Dimensionality Reduction
As we know data can be multi dimensional which can extent even to millions. Computation and visualization of such multi dimensioanl data is difficult and thus we want to reduce the dimension of the data (to pick the dimensions which can represent the data more).\ Dimensionality reduction is done by choosing the axis in the data space along which variance of the data is high.

-
and many other examples like data compression(using auto encoders), Generative models, density estimation, etc.
Why Unsupervised Learning?
- Unsupervised learning doesn't need labels.
- Making the training data for supervised learning is not easy. Its expensive, time consuming, labour consuming.
- The world has a lot of unlabelled data, which can be used directly or with a little pre processing for unsupervised learning.
Unsupervised Learning is still an ameature area of research, which has a lot of potential. Unsupervised learning is less expensive and can accelerate the AI field so much.